Posts by Bianca Jordan
Customer Churn Rate – Real Case Project

As the business world has evolved in the past couple of decades, one variable has become particularly valuable to understand – and as data scientist, you’ll be asked about it a lot – and that is: The Customer Churn Rate Customer “churn ” refers to the ratio of customers that have stopped or are going…
Read MoreDoes the ‘Quick Sort’ Algorithm Live Up to Its Name in Data Science?
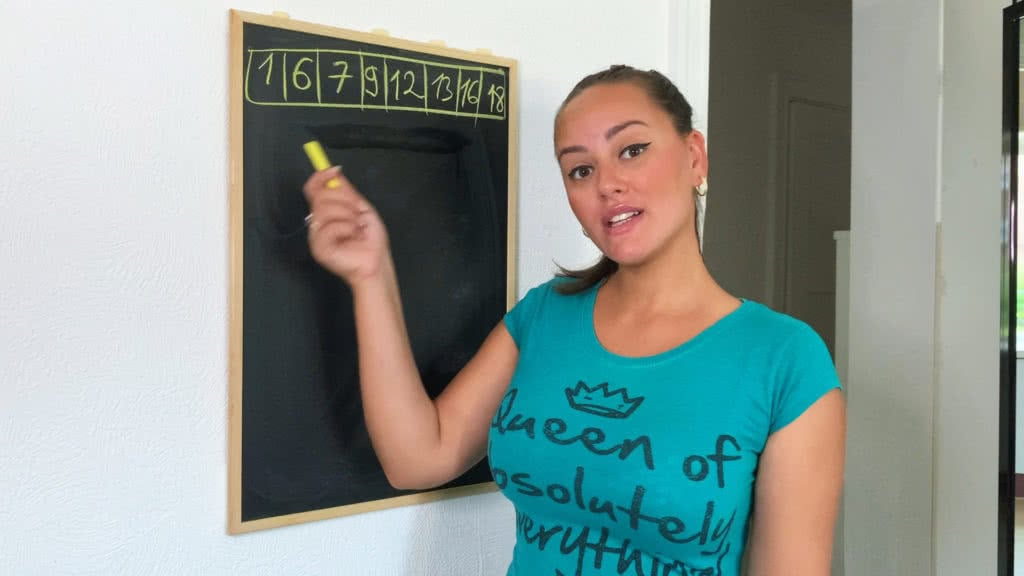
Fastest Sorting Algorithm? Knock Knock it’s Quick Sort here… I think you may have heard about me in class, or even from your friends or work. Anyway, in case you haven’t, I want to introduce myself. A lot of people that work with me say that I am the fastest sorting algorithm, with a time…
Read MoreMarketing-Mix Modelling

As the World is constantly on the lookout for new technological advancements, advertisement recommendations for sale leads become a necessity for New and Established business to differentiate themselves from their competition. This project explores Bayesian Mix Market Modelling and report the findings of the created Machine Learning model with the scope of predicting sales and…
Read More