As the business world has evolved in the past couple of decades, one variable has become particularly valuable to understand – and as data scientist, you’ll be asked about it a lot – and that is:
The Customer Churn Rate
Customer “churn ” refers to the ratio of customers that have stopped or are going to stop using a company’s services during a timeframe compared to its total customers. So basically when we talk about churn, we are talking about customer retention.
You can imagine how important that information is for companies with subscription models (gyms, Netflix, Amazon Prime), but all kinds of businesses would benefit from better understanding their churn: restaurants, retail, and even banks – which we will be focused on today with a real world example.
Banks need to be good at predicting everything, especially churn. If they don’t have a proper estimate for how long customers are going to stay with them, they can’t have a reliable estimate for how much money they have available for loans, credit, savings, anything. But the good news about banks is they have loads of data, so let’s take a look at a real world data set and see if we can predict churn.
If you would like to have the churn problem prediction in your portfolio here is a link to my tutorial where you can follow along through my step by step guidance.
Now if you remember my friend RIC, we talked about him in the “Learn to code fast” tutorial. In that video I mention that in the beginning of a big project like this, before we start coding, we first need to refer to our original question. What is it we are trying to solve? Well in this case we are trying to figure out what is the churn rate percentage of our bank customers.
Before we split our data, we need to figure out what are going to be the variables that will be the most important before creating our model. Let’s use our intuition and basically just guess and check which variables are relevant: age, credit score, and how long has a customer already been with the bank might be relevant. So let’s keep that in mind when we build our model.
After performing data analysis, cleaned our data and performed different visualisations in order to find the most relevant correlations between significant variables the results were as follows.
Customer Churn Analytics Results:
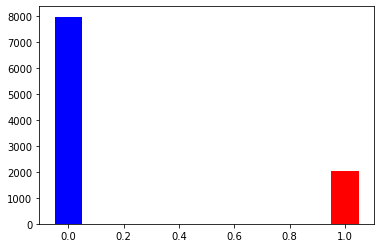
In the image above the first thing to notice is that our data is unbalanced, and we have app 80% of people that have not churned and app 20% of people that churned. Meaning that 80% of the bank customers are staying with the company which is a very good sign, but 20% are choosing to drop the bank´s services. Usually when dealing with unbalanced data, there are several techniques to handle this situation, most common and the one I have used in my tutorial is resampling of the dataset.
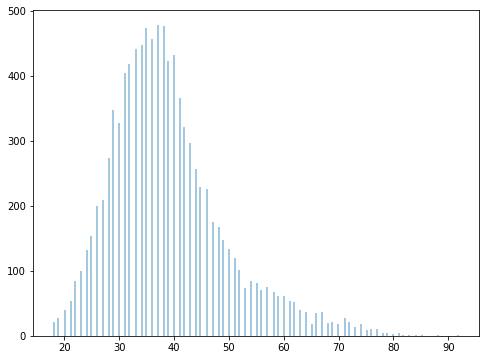
Whilst performing more data analysis you can see in the image above the majority customers of the bank are between the age of 30 mid 40s – 50s.
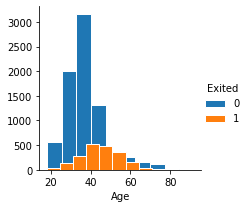
In the image above you can see a plot that checks the correlation between age and churn variables. We see that most churns are from people mid20s and 50s-60s. Data which could actually tell that usually people in their 20´s do not yet have a stable career and worklife, hence why they choose to churn, the same thing happening for people mid 50´s- 60´s where it can be quite tough to keep a workplace before going on pension. This being just an assumption, we will see if this assumption is right after we build our classifiers.

In the image above we see the correlation between geography and churn rate. Most churn rate proportional to its customers is in Germany. This metrics could be correlated to most likely the age of the customers in Germany as well as their income. (More to conclude after the results of our classifiers).
Machine Learning Classifier Results:
Moving on to classifiers, the first one I implemented was the random forest classifier, that has predicted a customer churn rate with an accuracy of 86.6% without any parameter tuning, result which is quite good. When I say that we have built our classifier, I mean we have previously done the prep work on our data, we Intuitively decided which would be the variables we would like to plug into our machine learning model, and then went ahead and added the prepped data into our classifier and performed the prediction.
After creating the classifier I have also checked the feature importance of Random Forest, which told me which variables are actually valuable and taken into consideration for a good prediction accuracy. From the plot we see that age, salary and credit score play a huge influence on how long the customers stay with the bank. As we saw from our visualisations above, a whole lot of people in their 20´s, with a smaller salary decided to churn, as well as people in their 50´s with the same issue choose to drop the banks services.
The second classifier we built is Logistic regression, with an accuracy of 80.2%, accuracy much lower than the random forest classifier. Here whenever we try to build a classifier our prediction accuracy rate should aim at 100%, of course 100% is pretty impossible to achieve due to the nature of the data, but the higher the prediction accuracy score the better your classifier performs.
Meaning, the better your machine learning model is at predicting the churn rate, the more you will know about your customers, and the more you could adapt your services to their needs. So a good classification result can ultimately result in more clients, and more stability for your business.
So why is it important to predict churn? Because usually the longer a customer is with you, the more money they are spending with you. But hopefully through this example you also see that the longer a customer is with you, the longer you are learning about them, but also learning about your own company.
When you understand customer’s spending habits you’re also learning about your own products – what accounts are performing well, which ones are not. What age is it useful to spend money on marketing to a client, which age is it a waste. There are answers to these questions, you just need the right data – because, luckily, data is a science.
I did the whole project along with your youtube video and this article gave me the detailed knowledge behind every step. Before reading this blog I knew the syntax of pandas, NumPy, and sklearn but didn’t know the actual use of them.
Also after this project, I have built self-confidence and crystal clear vision for my goal to be an AI engineer and data scientist.
Thank you so much Noor, it makes me very happy to hear you are more confident in your skills after following through with my tutorial. If there is any tutorial you would like to see next, don´t hesitate to drop me a line.
Hello,
Would it be possible to get the Churn Dataset?