blog
Customer Churn Rate – Real Case Project

As the business world has evolved in the past couple of decades, one variable has become particularly valuable to understand – and as data scientist, you’ll be asked about it a lot – and that is: The Customer Churn Rate Customer “churn ” refers to the ratio of customers that have stopped or are going…
Read MoreDoes the ‘Quick Sort’ Algorithm Live Up to Its Name in Data Science?
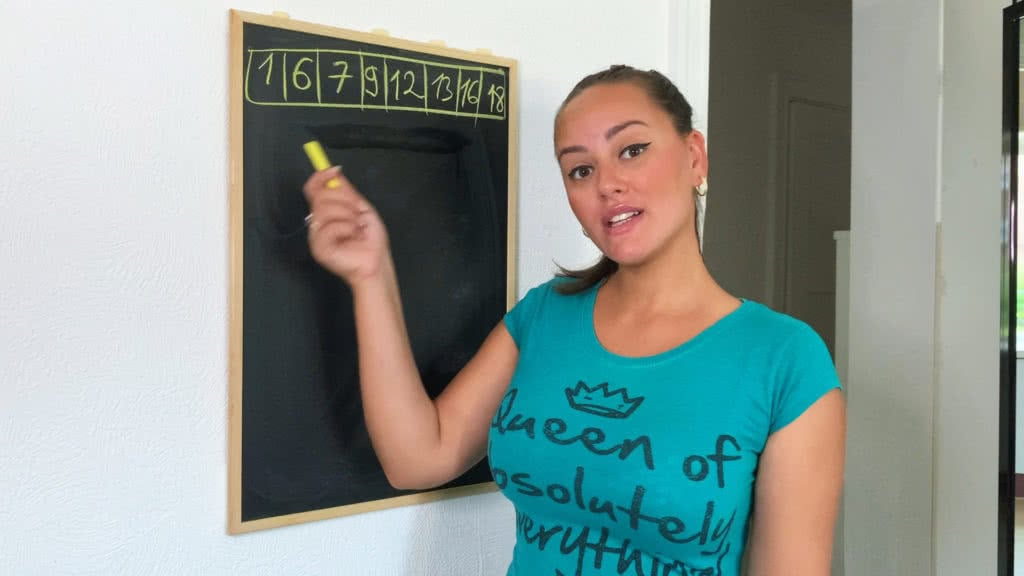
Fastest Sorting Algorithm? Knock Knock it’s Quick Sort here… I think you may have heard about me in class, or even from your friends or work. Anyway, in case you haven’t, I want to introduce myself. A lot of people that work with me say that I am the fastest sorting algorithm, with a time…
Read More